
I learned how to get around DALL-E Mini traffic so you don't have to.
Ranking Models to Illustrate a Children's Book With CONSUMER-Grade AI


If you don’t want to read and just want to use DALL-E Mini, use this notebook.
TL;DR
The biggest piece of advice I have to give is get away from sites that are hosting the models and start working in a notebook service like Google Colab. If you only want to use online portals, you’ll have longer wait times, get refused service due to high traffic, and have a lot more errors.
If you don’t want to bother with any of this & are interested in hiring an AI implementation consultant, reach out to us at redshoes.ai.

The Prince and The Pancake
A while back my puppy, Pancake, died unexpectedly. She was 10 months old. I decided to write a children’s book about all the wonderful things she taught our family. Especially our extremely cranky cattle dog Spanky, who we saw play for the first time because of her. It’s called “The Prince and The Pancake.”

I can’t draw my way out of a paper bag, but I can click a mouse and type. That makes me about as competent as 90% of the people posting about AI these days. So AI is my illustrator. However, all the cool images being shown off are made by models unavailable to the public. As long as I can't play with the big boy toys I'm done drooling over them. This article is about finding a solution that is available to CONSUMERS, like, RIGHT NOW.
What’s a Google Colab?
Google colab is a “notebook” service that reserves compute power (RAM, GPU) on a cloud server. You then configure it like you would any other computer to run the code. The benefit of the colab is that everything is laid out for you in a row and you just have to go down clicking play buttons (in order). No dependencies, git pulling, cd’ing into different directories and managing files: some other nerd before you has done that. A lot of models you can think of already have a colab notebook out there, and it’s as simple as going to “File” and clicking “Save a copy in Drive”

Model: DALL-E Mini on Huggingface
Rating: (Currently) Unusable.
AKA “Too much traffic”
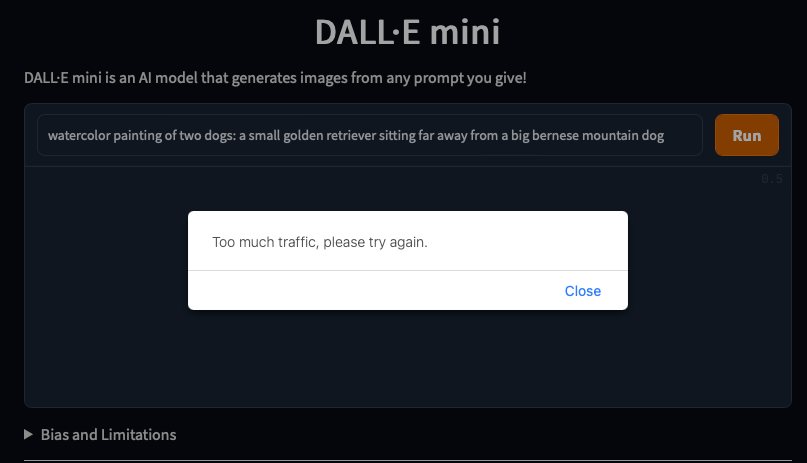
If you’re on the internet today, you’re probably actively removing years off some poor SRE’s life because you’re one of the million people trying to hit the magic funny image button. I’m lucky enough to have saved a relevant screenshot from before the internet discovered it.

I think the Huggingface version may in fact be different then the colab notebook that I use next, because I could not get anywhere near this level of image quality from that model. Potential reason for that:
The image you see below uses the prompt “cattle dog and bernese mountain dog sitting” not the test prompt “watercolor painting of two dogs: a small golden retriever sitting far away from a big bernese mountain dog”
The point above may indicate that the words watercolor and painting are spoiling things. I can see a decent argument for that, considering one of images below is actually a framed painting of a dog
Model: DALL-E Mini text-to-image (DALL-E Mini original)
Rating: Terrifying
Dall-e mini text-to-image is rough compared to the consumer grade models I tested below. It’s probably old. The major problem with it is that it’s gated behind some account stuff on wandb.ai, so if you don’t care to sign up for ANOTHER account, skip this one.
Another problem with using the DALL-E Mini text-to-image model is that it’s not yet had a high level “usability” passover to make the parameters manipulable, so you’re stuck to just giving it prompts.
The results are also terrifying and that doesn’t help. They are extremely reminiscent of Smile.jpg, if you’ve been hanging out in the dark corners of the internet long enough to know what that is.
Prompt: watercolor painting of two dogs: a small golden retriever sitting far away from a big bernese mountain dog

So another problem I ran into is that it seems certain breeds of dogs just weren’t well represented in the training data for this notebook. For example, I don’t think it really knows what a blue heeler looks like, or at least not how it’s different than a border collie. Though it did make one of the dogs blue. Almost all of them have heads too, so that’s a plus.
Prompt: watercolor painting of australian cattle dog
Model: Latent Diffusion LAION-400M text-to-image
Rating: Too Fun to Play With.
Here are the weights/prompts I’m using:

watercolor painting of two dogs: a small golden retriever sitting far away from a big bernese mountain dog

What’s interesting to me about these first examples is that if you have two objects of the same type but different subtypes, the model sometimes allows them to cross-pollute. Maybe good if you want to see what an as-yet uncrossed dog breed would look like?
Thing’s look worse and get scary again when I swap watercolor with impressionist. This model does not have a high opinion of impressionist art, it seems (please note the model in fact has no idea what art is, and is just hyper-correlating patterns of bits and then moving around other bits to recreate the patterns):

“Abstract impressionist” starts to show the true darkness.

Ok, I’m going to switch to 3-3 panels with smaller iterations so we arent’ taking up as much space. This is what those settings look like:

Here’s abstract impressionist without the word “painting” in the prompt. The first one is haunting. I think that removing painting actually dramatically improves results here.

When diffusion gets scaled up to 512 x 512, it starts to look a little wonkier, and really loves to make way more features than requested - I’m not sure why.

I call these ‘Dog Hydras’. It feels like the model is saying “Hey I can definitely do images larger than 256, totally, but wouldn’t it be cool if I just made more 256 images and put them in the same frame? Ok cool good talk".
Going for more iterations with fewer panels doesn’t change much unfortunately. Here’s 10 iterations with fewer panels

Here, I increased the stepcount to 100. I think I need to step back to 256x256

Ok, so stepping back to 256 fixed the problem of the long-neck hydra dogs, and reduced the number of the dogs that were in the frame back to what I asked for.

Steps 150:

500 steps:

Just for fun, I decided to ball out on maximalist settings. 500 steps, 512 pixels. The results were fun, but the time cost of increasing steps isn’t worth it. The image below took about as long to generate as every other image you’ve seen in thus far combined.

Model:DALLE-E Mini Inference Pipeline (DALL-E Mega)
Rating: Best combination of usability, accuracy, and fun.
Alright this notebook blows the one at the beginning out of the water. Definitely what Huggable is serving as their model. Mind you, I found these things through google searching stuff so there was no guarantee of quality to begin with. This model clearly has been trained with data that better differentiates subcategories. I used our standard prompt about with the watercolor and the painting and the goldens and the berners and GLAVEN!


Wow! It can tell the breeds apart! Amazing!
For an extra treat, when I remove “watercolor,” it gets all wavvy and cuts off its own ear. Take that diffusion! That’s what you get for not knowing what impressionism is.
It even knows what cattledogs are some of the time!

This model is the best of the 3 we looked at today for my usecase. It hits that sweet spot of figurative rendering, style, and ease of use.
Speaking of ease of use:
There’s one hiccup as I mentioned in the first DALL-E Mini section, you need to go create an account on wandb.ai and then copy your API key.
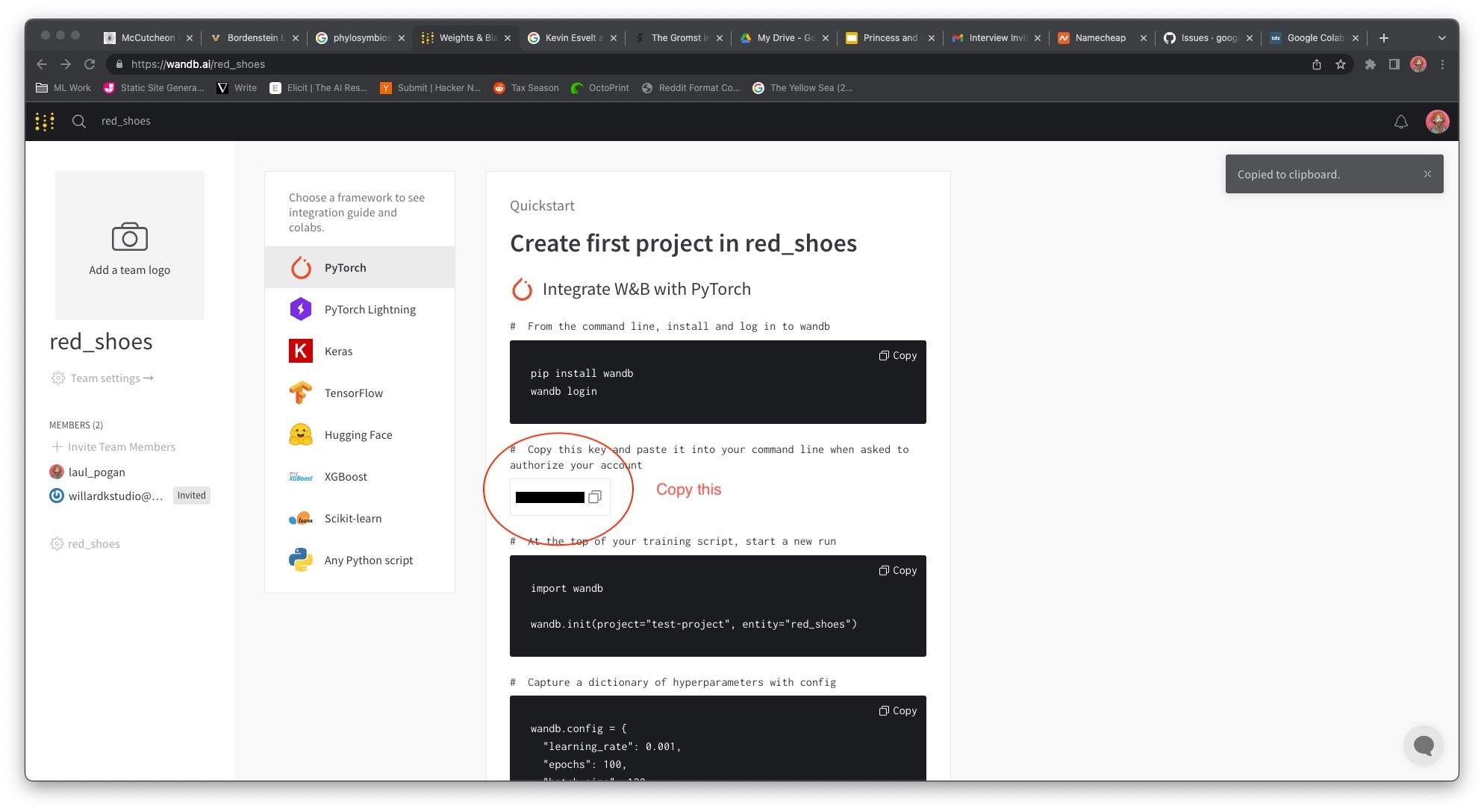
Then you need to go enter it into the model.
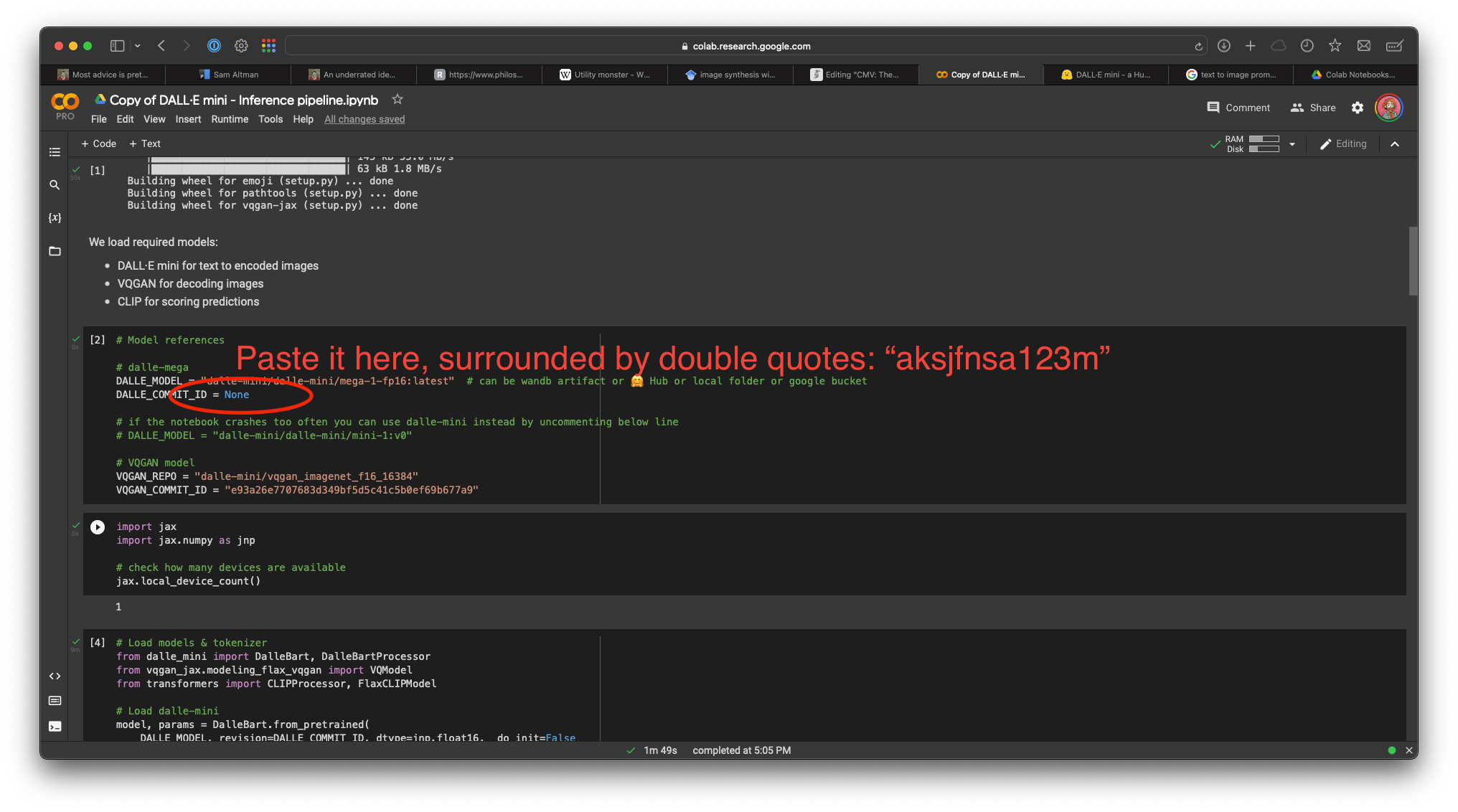
Click on the play buttons in the order they appear on the page, follow the prompts, and you’re in.
Another side note: Depending on server load, this last model might use too much RAM since it’s actually DALL-E Mega, which is much heftier than mini. If you aren’t able to get it to run despite all the set up, or if it crashes too much, you can switch back to DALL-E Mini by uncommenting the line shown here:

You can also instead pay for a colab pro subscription, which will boost your available RAM enough to run the model no problem.
Things that I didn’t try today but will in the future:
The Dalle-E Mini models take multiple prompts at once, I felt that would confuse things and will be experimenting more with it in the future. It can apparently increase the speed of inference
Vdiffusion is another model that doesn’t have any notebooks that are quite so user friendly as the ones we went over today.
Scaling the images up. Of course it’s cool to create grids, but there’s an entirely different world of image scaling that I may write about later.
Conclusions
Go look at the TL;DR from the beginning dummy.
Models have trouble telling subcategories apart
Web interfaces are dumb
Use a notebook service.
If you’re interested in hiring an AI implementation consultant, please contact us at redshoes.ai.
If you enjoyed this post, comment saying what you liked. Then SHARE IT!
If you want more weird, funny stuff like it, SUBSCRIBE!
If you just want to say mean things to me on the internet, my twitter is @laul_pogan.
Goodnight, and good luck, all you weird lil chili peppers.
just to point out, dalle mega has been renamed crAIyon and the issue with traffic has solved (hopefully) but I'm also getting errors in the pipeline code, though thankfully that will no longer be an issue as the developers of dalle mini/mega have learned from the lesson and now crAIyon works without the traffic errors
so as an update to my issue I decided to pay the piper and buy collab pro, it's working now but I'm not getting near as good predictions as you (the op) and I wanted to know how you got such good results with dall e mega
edit: also want to point out that I'm getting the error "invalid index to scalar variable." on the line print(f"Score: {jnp.asarray(logits[i][idx], dtype=jnp.float32):.2f}\n") and I can't figure out a solution related to the error and this specific line of code