
The Persistence Problem: Lessons learned from illustrating a children's book with GPT-3 and crAIyon.
A retrospective on my first AI-coauthoring experience.


What is this project?
I’m co-authoring a children’s book using AI text-to-image models as my illustrator. Recently I published the first draft of my AI-illustrated children’s book.
Alright, you caught me- it’s more like the 5th draft, but it’s the first one that includes work from my lovely co-author: crAIyon (they changed the name from Dall-e MEGA/mini to avoid copyright issues with OpenAI).
In my first article on this project, I held text-to-image model try-outs to see which lucky algorithm would get to be my illustrator. Today I’ll be continuing on in the “learn-out-loud” fashion.
What’s the story with the book?
In early 2022 my beloved puppy Pancake passed away unexpectedly. I vowed to make a book about all the love, joy, and growth she brought our family.

However, Pancake is only part of the larger story around why I’m using AI to illustrate this book.
At the beginning of 2022 my best friend from childhood, Willard, and I started an AI implementation consultancy. We’ve been under contract with a client doing image-to-image synthesis of fake woodgrain, so I haven’t had much time to sneak away to work on personal projects. Both Willard and I believe in using personal interest as an avenue to push learning and training of our models to further heights. He’s spent free time fine-tuning GAN’s to generate new Shin Megami Tensei demons, and has inspired me to pursue new horizons of learning in my own artistic expression. I almost gave up on writing The Prince and the Pancake due to my inability to produce any variety of artistic rendering, but Willard encouraged me to pursue illustration with text-to-image models.
Why a children’s book?
Pancake was only 10 months old when she passed, so the story was best suited to short-form from the outset. However, there are a large amount of implicit benefits from using a children’s book as the testing grounds for text-to-image synthesis:
The roughly 50-50 split between visual and textual information means that we’ll be relying on AI to tell part of the story, rather than just illustrate a cover, as a lot of the claims of “first AI-illustrated” novels are just cover art.
Children’s books are generally 32 pages long and 500-1000 words. This is a well-constrained problem space with a minimal amount of text, which makes it ideal for under-limit access to models like GPT-3’s
text-davinci-002, which maxes out at 4,000 tokens for both combined prompt and response per request.It makes sense now that AI has reached an elementary-school level that we could ask it to help produce kindergarten content. Relatively simple language and content should lead to cleaner output images and prompts. Deep, thematic significance and complex action scenes aren’t yet in the wheelhouse of text-to-image models (not without a lot of cajoling). 1
Using GPT-3 to generate image prompts.
Disclaimer (confusing language): when giving GPT-3 input, you can “prompt” it with a request to do something. Since I asked the model to return more prompts to feed into other models, it’s important to remembering that in these examples GPT-3 is both taking and returning prompts.
For me this project is more about developing and validating a solid workflow for how AI coauthors can be leveraged in the future. I could hand craft individual text to image prompts on a per-page basis, but to me that’s both a lot more work and not as interesting. I decided to use GPT-3 in the hopes that it might be able to reduce workload while solving the persistence problem, which we’ll talk about further down the page.
All of the return prompts I’ve shown here were generated from the 3rd and 4th drafts of the book’s manuscript- which were handwritten by me without help of any AI. You can see the unformatted field notes and raw output of my investigation here.
As input, I submitted the request prompt followed by the entire text of the story labeled by page. This is the general gist of the input prompts I was providing to GPT-3:
Give a text to image prompt describing an illustration for each page:

Lessons learned during GPT-3 text-to-image prompt generation:
Token economy: Word count matters, a lot. There’s a sweet spot between providing the model a good amount of information to reason with, and being so sparse it just repeats exactly what you told it in different words. The trade off between the two is that due to token limits, the bigger the input, the smaller the response. Upping the temperature from the base .7 can inject variance as your input gets more sparse.
Cut the Chaff: Chapter headings appeared to have no effect on GPT-3’s accuracy or organization, so they were cut between drafts 3 and 4 to save on tokens. Lots of whitespace in the text seemed to effect the model’s likelihood to correctly follow requests to generate per-page image prompts, and was also aggressively cut between drafts 3 and 4. I don’t think this is any sort of significant signal of model behavior. It was likely just normal variance that I’m going all apophenic on.
Correct execution of request prompt: I found that temperatures above .8 were less likely to return a text-to-image prompt for every single page, often returning between 11-24 prompts, as opposed to the requested 32.
Request Prompt Shaping: Leaving out specific requests for per-page return prompts also led to the model returning too few text-to-image prompts for the number of pages provided, even if the input was specified as a children’s book and tagged with pages.
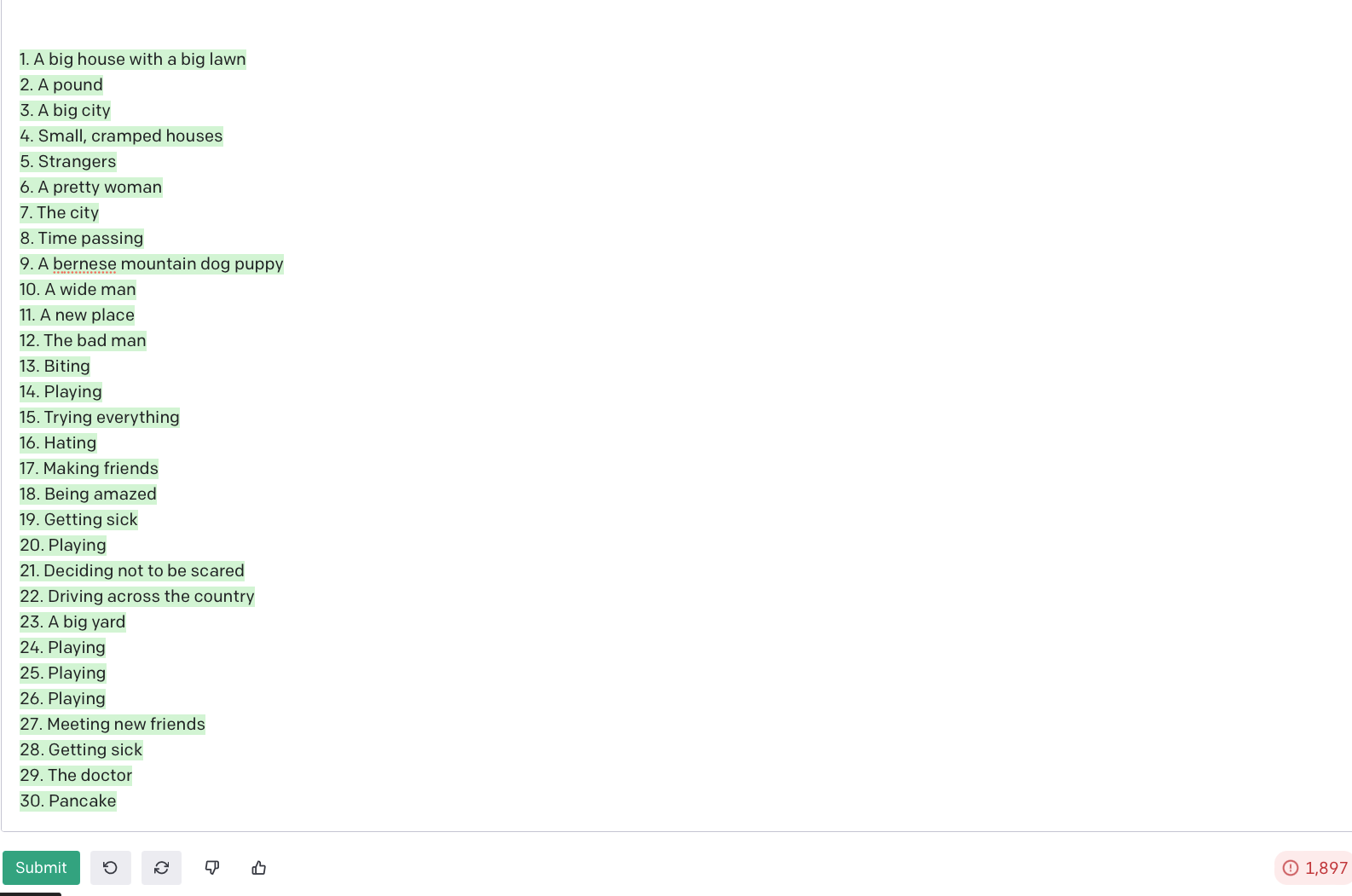
Keep it simple: Adding in words like ‘vivid,’ ‘detailed,’ ‘imagery’, ‘action,’ and ‘background’ had the tendency to cause the model to wildly misinterpret my desires. At one point it just spit out a list of nouns:

Ah yes, I’m sure Dall-e 2 can create some beautiful art of “Playing” 3 pages in a row. I found that just asking it to supply a text-to-image prompt for each page was the best way to consistently get all 32 pages with decent return prompts.
The prompt I ended up using to get GPT-3 to give me image prompts for the draft from yesterday was:
This is the transcript of a children's picture book. Could you give me a text to image prompt for each page?
However, by far the most interesting set of returns came from this prompt:
For each page, describe the imagery in the scene as if it were a text to image prompt for DALLE-2:

This was the sort of result I was hoping for when I decided to use GPT-3 to generate prompts. However rudimentary, this shows the ability to represent the same character showing up in multiple scenes sequentially. It’s time to talk about the persistence problem.
What is the persistence problem?
Disclaimer #1 (Qualifications): I’m no AI researcher. I did about half an hour of research trying to find out if there was already a name for this problem but was unable to find one. Let me know in the comments or on twitter if you’re familiar with an extant naming convention.
The persistence problem is the issue that exists when serially generating images from a set of text prompts. I’m trying to tell a story about two dogs, and the images won’t exactly be coherent if on one page a golden retriever and a german shepherd are main characters, but on the next it’s a Chihuahua and a pit bull.
The issue here is that text-to-image models don’t have memory of their previous runs. You can do things like supplying image prompts or initialization images, but those are better suited to transforming an existing scene, rather than creating a new one with the same characters.
Hence the name, persistence problem. It’s a problem in persisting elements from one image to the next coherently in a visual narrative. I did find one model in my research that seems to be addressing this issue: Make-A-Scene. For the next draft I’ll be demoing it to see if it offers a solution to the persistence problem.
I firmly believe in trying to solve problems in the stupidest, most obvious way you know how from the outset. As your understanding of the problem space develops, so does the sophistication of your solution. My very first attempts were to edit the prompts that GPT-3 was spitting out to replace character names with descriptors. It was cumbersome, but worked decently well. I decided to speed up the process a bit and push the burden of ctrl+f onto python:
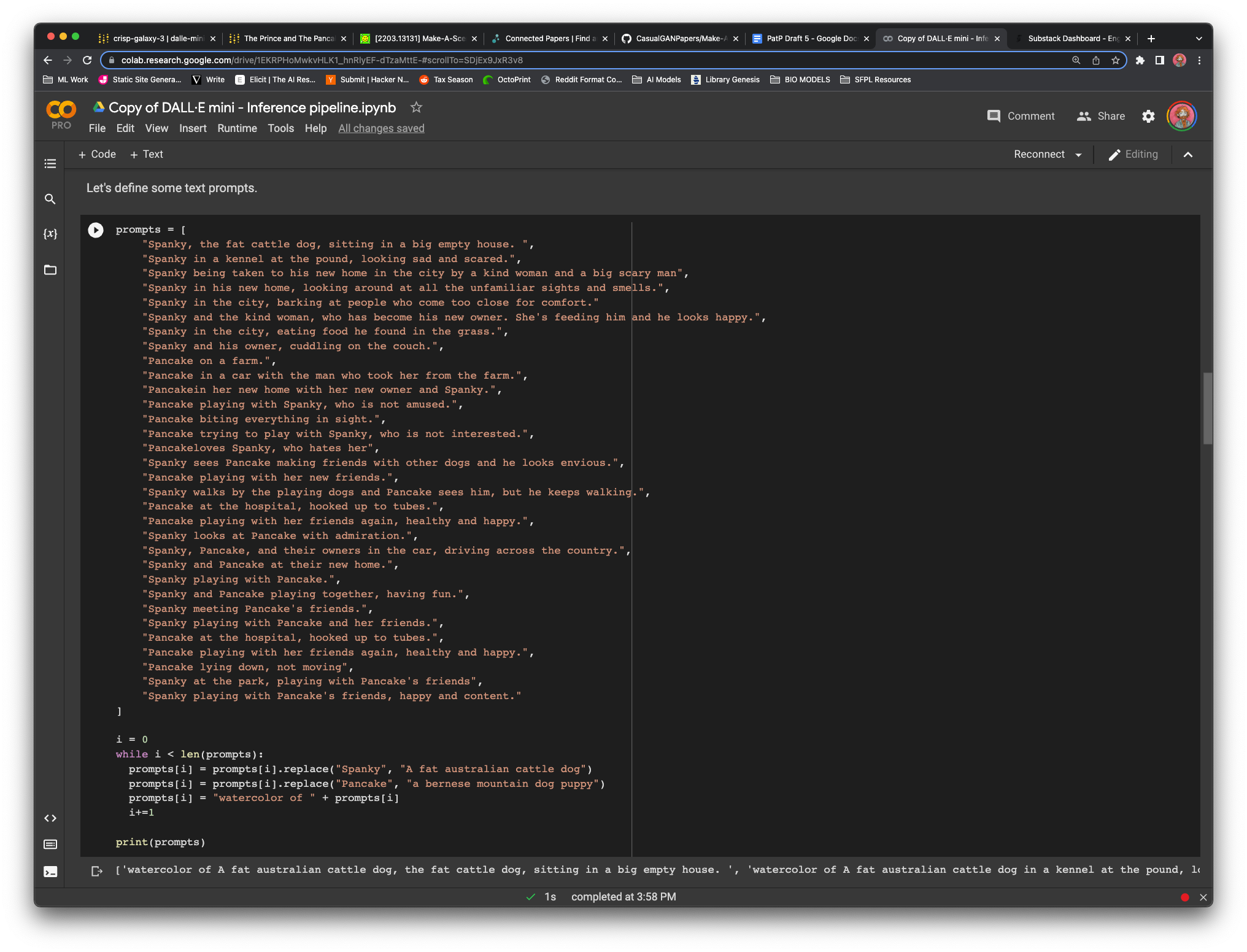
Preprocessing prompts before they go into the model is my clumsy first attempt at tackling the persistence problem. It works very well at reducing manual overhead in processing generated image prompts. The best thing about dumb solutions is that their results, though often unsatisfactory, point very clearly to next steps for improving our approach.
Using crAIyon for text-to-image generation

I used the DALL·E mini - Inference pipeline notebook featured at the end of my previous article to generate images using the prompts GPT-3 returned. In general I feel that the images I got back could be composed by hand into something sensical for each page, there’s a big gap between that and an automated workflow that shows some level of an AI “visual imagination”.
There are other models besides crAIyon out there. I’ll likely try a second draft using DALL-E Flow (notebook), which adds a step of human interface to select the best generated images from crAIyon before processing and upscaling them to add more detail. I shied away from using Flow for this stage of the project because I really wanted to get a feel for what the models could do with minimal help other than prompt pre-processing.
There’s also Midjourney, which has a lot of interesting content but is limited to a discord bot interface, which has kept me away thus far due to not actually being able to futz with the model or code. I mentioned Make-A-Scene above, which seems promising from the paper.
The big question is whether a fancier model would solve the issues I’m currently running into with persistence and detail. As long as I insist on running every page at once through GPT-3 to “imagine” the scene from text, I’m fighting with one hand tied behind my back.
Lessons learned from using crAIyon for draft 1:
Multi-prompt: Running the model with all 32 prompts at once saved me an enormous amount of time in comparison to the one-by-one runs I did for my previous experiments. If you’re working on a similar project, I suggest batching prompts to save time.
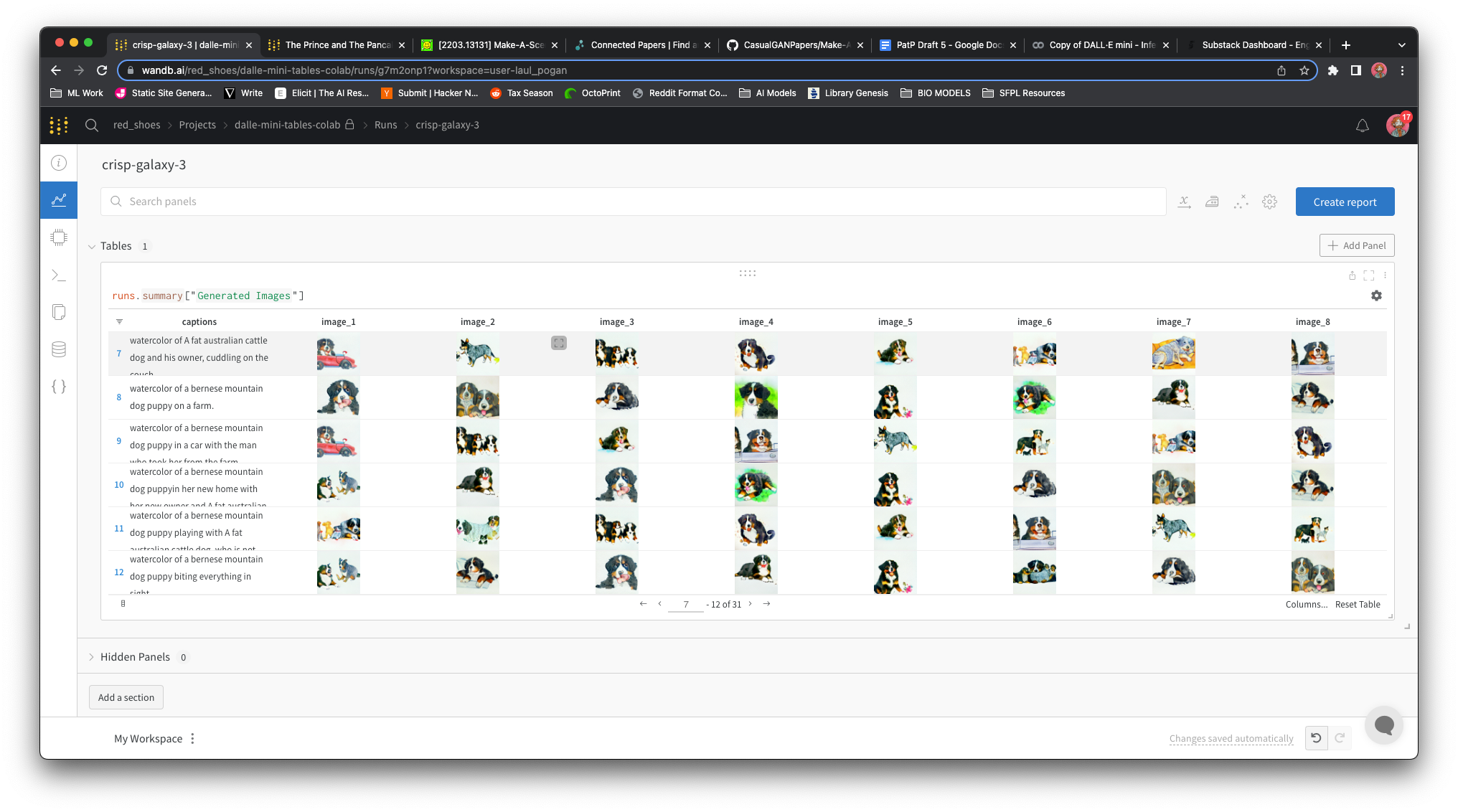
CLIP ranking is only useful to a point for figurative depiction: I didn’t write on the CLIP ranking step last time because it isn’t very useful for this application. Since I’m not looking for photorealism, I often found the best image return for a given prompt in the middle of the CLIP rankings rather than at the top. If you’re running a similar project, you should still look through each output.
I still had to hand select the right images for each page: Due to the similarity of a lot of the GPT-3 prompts, some returns for one page ended up being much better for others. After all the commotion I still ended up having to curate the results in order to get sensible narrative images, a big hurdle I’ll need to jump in coming iterations.
White Room Syndrome: Most of the return images didn’t have a background; they just displayed characters floating in a featureless white void. If they did have background, it was only the slight suggestion of one. I need to investigate to see if this is a problem better solved with more detailed prompts, or a second round of processing on images to add backgrounds.
WandB reports integration needs work:There’s a snippet of optional code at the end of the inference pipeline notebook that exports the run data to weights and balances for viewing.This code isn’t functional out of the box:
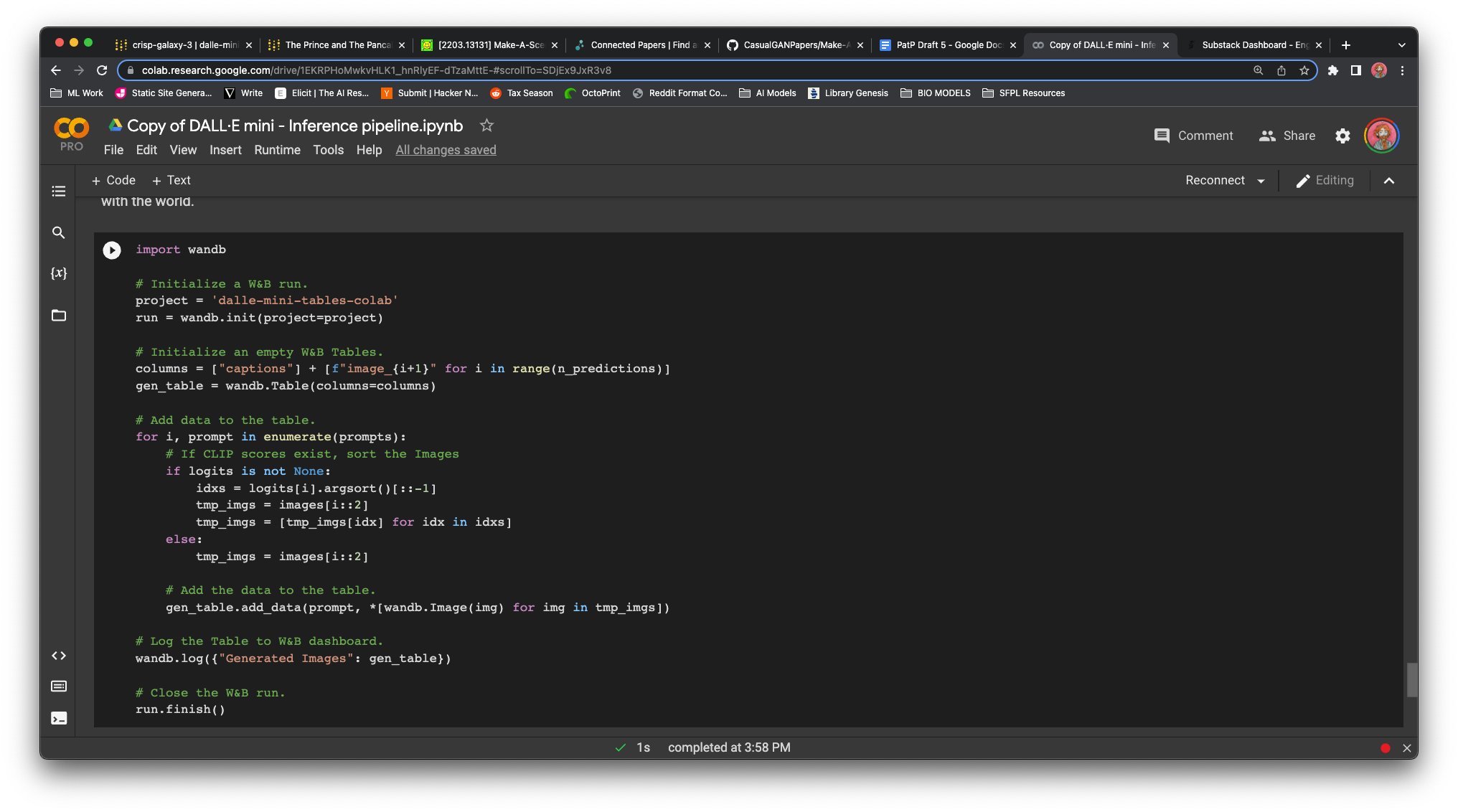
EDIT: WandB got back to me and fixed this issue almost instantly. Color me impressed!
Though crAIyon is great and blows a lot of other models out of the water in depiction, this draft has made it clear that it can’t do the job alone. Additional processing steps will needed to be added either in prompt creation, image post-processing, or both. At this point it doesn’t seem possible to achieve satisfactory results without significant human intervention.
Conclusions and Next Steps
Today we took a crude pass at a workflow for illustrating a children’s book with AI. We used GPT-3 to generate image prompts from natural text, and then fed them into crAIyon to get images. Running around between all of these different models is time consuming, but much less-so than hand-crafting each individual scene description.
There’s a lot of work to be done in addressing the persistence problem, as depiction of characters between scenes remains inconsistent. While this isn’t a huge problem for goofy watercolored children’s books, it’s a significant one for graphic novels and any visual narrative that’s aiming for a higher level of sophistication.
It was ambitious to attempt to generate text-to-image prompts with GPT-3 at this stage in the project, and I think it wound up being equal parts boon and dud. There’s need for a more labor intensive approach in future iterations to see if it’s possible to get higher quality results at the expense of time by hand-writing image prompts and running them through multiple layers of processing.
As always, please like, share, comment, and subscribe.
Finally, if you’re in need of some scrappy dudes to help you on your AI adventure, don’t hesitate to reach out to Willard and I at redshoes.ai:

Press X to doubt. This claim needs more investigation, especially considering the white room syndrome on display.